
Fake Userland
Dá pra ter Userland sem User Mode? Dá sim, se o conceito for amplo


Esse P2 não acaba, hein? Enquanto no último post tratamos de primitivas de sincronização para as threads, agora vamos adentrar em uma área que praticamente todos nós lidamos diariamente: Processos e Modo Usuário.
Quer dizer, mais ou menos. Fazer isso de modo completo exigiria interrupções, paginação e mudança de permissões do processador, e não temos nenhuma das duas ainda. Não por negligência ou desleixo, uma parte disso será feita no próximo trabalho. Mas se não temos nada disso, como podemos falar em Modo Usuário?
Vamos ver o que é pedido no P2 sobre isso:
In future projects, processes will have their own protected address spaces and run in a less privileged protection ring than the kernel. For now, however, there are only slight differences between threads and processes. … Moreover, process code is not linked with the kernel, thus the need for the single entry-point mechanism (see how syslib.S:kernel_entry is called).
Então, para esse trabalho, um processo não é muito diferente de uma thread. O processo será compilado de forma “autônoma”. Não temos nada de interrupções, então não temos o conceito de carregar o executável do disco. O que vamos fazer é definir os endereços de entrypoint dos processos, e alterar o utilitário createimage para “colá-los” na imagem do kernel.
A beleza da coisa é que, tanto na ida quanto na volta, a única informação que o kernel tem do executável do processo é o seu entrypoint. E de forma similar, o processo só conhece um ponto de entrada para o kernel, que no trabalho eles chamaram de chamada de sistema.
Nesse trabalho, no momento, temos as quatro threads do post anterior e adicionaremos dois processos. O layout da memória ficará assim:

O createimage espera receber agora os executáveis do bootloader, kernel e processos, ordenados pelo entrypoint, conforme imagem acima. A imagem é então muito maior do que o código efetivo; isso porque o createimage inserirá padding do fim do kernel até o início do processo 1, do fim do processo 1 até o início do processo 2 e assim por diante.
O createimage acabou ficando mais simples, já que ele corre o argumento do argv lendo o ELF e juntando tudo. Segue um trecho do arquivo alterado, e se quiser ver completo, visite meu github:
...
int main(int argc, char *argv[]) {
bool extended = false;
std::ostringstream output_string;
std::vector<u_int8_t> bytearray;
int image_counter = 0;
for (int c = 1; c < argc; c++) {
std::string arg = std::string(argv[c]);
if (arg.compare("--extended") == 0) {
extended = true;
} else {
std::ifstream exec_if(arg, std::ios::binary);
if (exec_if.fail()) {
std::cerr << "Error: Can't open ELF file: " << arg << std::endl;
return 1;
}
std::vector<Elf32_Phdr> exec_hs = read_exec_file(exec_if);
extract_segments(arg, exec_hs, exec_if, output_string, bytearray);
exec_if.close();
}
}
...Depois, escrevemos os processos. Segue o process1.cpp:
#include "include/syslib.h"
#include "include/util.h"
class Test {
public:
int x;
Test() : x{15} {};
};
Test y;
int main() {
set_display_position(20, 0);
Test t;
printk("Hello World! t.x %d - ", t.x);
printk("Hello World! y.x %d - ", y.x);
t.x = t.x + 100 + y.x;
printk("Hello World! t.x %d\n", t.x);
printk("process1 is yielding\n");
yield();
printk("process1 woke up and is exiting...\n");
return 0;
}E o process2.cpp:
#include "include/syslib.h"
#include "include/util.h"
int main() {
set_display_position(23, 0);
printk("process2 ");
int i = 0;
while (i++ < 15000) {
set_display_position(23, 9);
printk("%d", i);
yield();
}
printk("\nprocess2 finished!");
return 0;
}Se você é perspicaz (e você é, e eu também, como diria o Cortella), percebeu duas coisas nos códigos acima: 1) usamos a função main como função principal; e 2) há a invocação da syscall yield, mas não da exit. Pode isso, Arnaldo?
Pois é, isso não está no P2, mas como estou usando C++ em tudo, me perguntei se conseguiria usar classes, ver se os construtores estão funcionando etc. Obviamente, quando comecei a fazer percebi que não estavam :D mas consegui preparar o código até que isso fosse viável. “E como você fez isso?”, você me pergunta. Ótima pergunta, aliás.
Bom, na real não é muito diferente de como fizemos no kernel. Temos que envolver os códigos objetos dos processos nos nossos velhos conhecidos crti.o crtbeg.o <OBJETO> crtend.o crtn.o. Assim conseguimos invocar as funções _init e _fini, que, você já sabe, invoca os construtores e destrutores. Mas quem invoca essas funções?
Ah, essa é a beleza da coisa. Enquanto, no caso do kernel, nosso próprio kernel É o entry point e deve chamar tais funções, agora cada processo deve ter um processo de inicialização, mas que ainda assim, seja transparente para ele, como é nos códigos acima.
E com isso, criei o crt0.cpp:
#include "include/syslib.h"
#include "include/util.h"
extern int main();
extern "C" void _start() {
_init();
main();
_fini();
exit();
}Você viu a beleza da coisa? Você percebe como a natureza é maravilhosa? Quando Deus desenhou o processador, ele estava namorando (já no caso do x86, ele estava de ressaca com certeza, mas isso não vem ao caso). Esse é o nosso verdadeiro entrypoint, chama o construtor, chama a main (função externa à unidade de compilação crt0.cpp, afinal, a main está nos arquivos process1.cpp e process2.cpp). Ele finaliza executando a lista de destrutores na função _fini, e por fim, chama a syscall exit. Perfeito!
Para você entender como isso é montado no Makefile, veja abaixo um exemplo para o process1.cpp. É igual para o process2.cpp e demais processos que venham a surgir.
...
UOBJS:=syslib.o util.o screen.o
CRTI_OBJ=crti.o
CRTBEGIN_OBJ:=$(shell g++ -m32 $(CFLAGS) -print-file-name=crtbegin.o)
CRTEND_OBJ:=$(shell g++ -m32 $(CFLAGS) -print-file-name=crtend.o)
CRTN_OBJ=crtn.o
...
UOBJ_LINK_LIST_BEG:=crt0.o $(CRTI_OBJ) $(CRTBEGIN_OBJ)
UOBJ_LINK_LIST_END:=$(UOBJS) $(CRTEND_OBJ) $(CRTN_OBJ)
...
process1: $(UOBJ_LINK_LIST_BEG) process1.o $(UOBJ_LINK_LIST_END)
cd $(OUTPUTDIR) && ld -O2 -g -m elf_i386 -T../linker.ld -Ttext 0x10000 -z noexecstack -o $@ $(UOBJ_LINK_LIST_BEG) process1.o $(UOBJ_LINK_LIST_END)Usamos o mesmo arquivo do linker do kernel (-T../linker.ld), definimos o entrypoint do processo (-Ttext 0x10000), e envolvemos o código objeto do processo com os outros códigos objetos $(UOBJ_LINK_LIST_BEG) process1.o $(UOBJ_LINK_LIST_END). Ao executar o comando make, essa linha resulta em:
cd build && ld -O2 -g -m elf_i386 -T../linker.ld -Ttext 0x10000 -z noexecstack -o process1 crt0.o crti.o /usr/lib/gcc/x86_64-linux-gnu/11/32/crtbegin.o process1.o syslib.o util.o screen.o /usr/lib/gcc/x86_64-linux-gnu/11/32/crtend.o crtn.oE os UOBJS? Bom, util.o e screen.o são exatamente os mesmos do kernel, eles escrevem no endereço 0xB8000, ou seja, a memória de vídeo. Mas tive que alterar e voltar a posição do cursor e cores para variáveis globais no arquivo screen.o. Isso porque antes eu tinha colocado no PCB (cada thread/processo teria sua própria posição e cores), mas o processo não tem informação nenhuma do kernel, e isso inclui o PCB… Precisei voltar a como estava. O screen.cpp agora está assim:
#include "include/screen.h"
static DisplayChar *video_memory = (DisplayChar *)SCREEN_ADDR;
static int display_position = 0;
static char current_color = (GRAY & 0x0f) | (BLACK << 4);
...Mas há uma consequência nisso. No código do kernel, há um screen.o ligado. Mas agora há um screen.o ligado ao process1.o e outro ao process2.o. Significa que as threads do kernel compartilham essas variáveis globais, mas cada processo tem suas próprias variáveis.
E o que tem em syslib.cpp? Vejamos:
#define SYSCALL_YIELD 0
#define SYSCALL_EXIT 1
#include "include/util.h"
void (**kernel_entry_point)(int) = (void (**)(int))0x00F00;
void yield() { (**kernel_entry_point)(SYSCALL_YIELD); }
void exit() { (**kernel_entry_point)(SYSCALL_EXIT); }MEU DEUS QUE CÓDIGO PROFANO É ESSE? Você é muito previsível, se acalme que eu já explico. Vamos ver o que o P2 fala sobre syscalls:
This project uses a dispatch mechanism to overcome the difficulty of processes not knowing the addresses of do_yield() and do_exit(). kernel.h defines a spot in memory called ENTRY_POINT at which _start() writes the address of the function label kernel_entry (in entry.S) at run-time. When a process calls yield() or exit() (in syslib.S), SYSCALL(i) (in the same file) gets called with an argument that represents which system call the caller wants (yield or exit), similar to how a number was stored in %ah before initiating a BIOS interrupt. SYSCALL(i) in turn calls kernel_entry, whose address was saved at ENTRY_POINT. kernel_entry saves the process's context to its PCB and then transfers control to either of the previously "unreachable" do_yield() or do_exit() functions. Like threads, something must restore the processes' context after it is chosen to run again by scheduler.
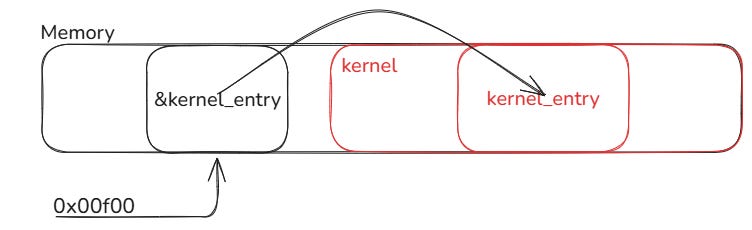
Lembre-se da imagem acima:

A única coisa que os processos sabem sobre a memória é isso ai, o endereço do entrypoint para o kernel. Mas se você é esperto (e você é, e eu também), sabe que quando o _start do kernel é invocado, não tem nada útil nesse endereço. Afinal, o bootloader joga o kernel a partir do endereço 0x1000, que é maior que 0xf00. Acontece que a própria _start acessa o endereço 0xf00 e coloca um outro endereço nessa memória, que é o endereço da função kernel_entry!
...
#define USER_ENTRY_POINT 0x00F00
...
extern "C" void _start() {
...
*(uint32_t *)(USER_ENTRY_POINT) = (uint32_t)&kernel_entry;
...Ou seja, a posição 0x00f00 é um ponteiro para um ponteiro de função, e a função é a kernel_entry. Por isso, os dois ** na declaração:
void (**kernel_entry_point)(int) = (void (**)(int))0x00F00;Se você é meio burro (e você é, e eu também), talvez a imagem abaixo facilite o entendimento:
Depois nós vemos certinho como (**kernel_entry_point)(SYSCALL_YIELD) e (**kernel_entry_point)(SYSCALL_EXIT) são executadas. Antes disso, vamos ver o que é necessário alterar no PCB para comportar a execução de processos.

E:
kernel_entry saves the process's context to its PCB and then transfers control to either of the previously "unreachable" do_yield() or do_exit() functions.
Então, nós salvávamos o contexto na scheduler_entry para as threads, e agora precisamos salvar logo após entrar em kernel_entry também. Apesar que isso não é obrigatório NESTE trabalho, porque:
Threads only run in one context: the kernel. Processes have two contexts: user and kernel. You have an option in this project to decide how you want to deal with this. One option is to make room in your PCB for both contexts. The other option is to only leave room for one context and lose any kernel context for each process after crossing the user-kernel boundary. This is ok because there is not state that needs to be kept within the kernel for processes. However, if you choose to explicity save both, it is ok to "waste" space in the PCB for threads that won't use the user context area.
Mas estou construindo este kernel baseado em um trabalho escolar. No próximo trabalho, quando interrupções de software estiverem habilitadas, uma chamada do sistema do usuário poderá ser interrompida. Então, vai por mim, é melhor já deixar isso pronto agora.
Não há grandes alterações no PCB, a gente reserva espaço para salvar o contexto do usuário:
...
class PCB {
uint32_t kregs[9]; // EDI, ESI, EBP, original ESP, EBX, EDX, ECX, EAX, EFLAGS
// (KERNEL MODE)
uint32_t uregs[9]; // EDI, ESI, EBP, original ESP, EBX, EDX, ECX, EAX, EFLAGS
// (USER MODE)
...E agora, a parte delicada do trabalho, feito em assembly. Vamos adentrar no covil da kernel_entry. E, de novo, depois de pronto, parece fácil, mas perdi um tempão tentando depurar um problema de estouro de pilha. Se a pilha não for restaurada corretamente entre as chamadas e salvamento de contexto, qualquer laço de 10, 15 mil iterações que chamem troca de contexto, usando yield por exemplo, com pilhas de tamanho 4KB, o estouro de pilha vem e você nem percebe.
O fluxo de chamadas segue então a imagem abaixo:
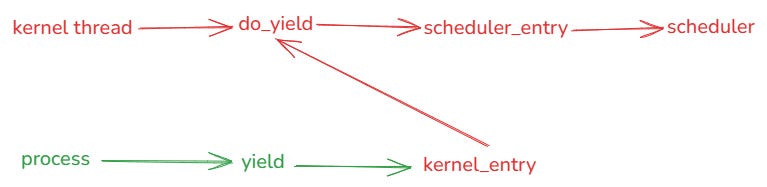
Enquanto as threads de kernel tem acesso direto a função do_yield, o processo precisa fazer a chamada de sistema yield, que invoca a kernel_entry, e esta é responsável por invocar as funções de kernel, no caso, a do_yield.
Mas e agora, como se faz para salvar o contexto e restaurar o próximo? Aqui as coisas começam a ficar interessantes. Para as threads de kernel, nada é alterado, isso já está funcionando. Para os processo ao entrar na função kernel_entry, estamos no contexto do usuário, com a pilha do usuário. Devemos nesse momento chavear para as pilhas (e registradores) de kernel (em nome desse processo. Não das outras tarefas do kernel). Nisso, a chamada de sistema chamará ou a do_yield ou do_exit. Essas funções, você já viu: elas invocarão a scheduler_entry, e essa função salva o contexto de kernel do processo. Nisso, o escalonador escolhe outra tarefa, restaurando seu contexto de kernel. Caso essa tarefa seja um processo, significa que ele obrigatoriamente chegou até aqui via kernel_entry. Portanto, salvamos novamente o contexto de kernel do processo, e restauramos o contexto de usuário, e retornamos da chamada de sistema. Ufa!
Confuso? Talvez uma imagem ajude a ilustrar melhor. Essa parte é enjoada mesmo, leve seu tempo para entender o que está acontecendo.
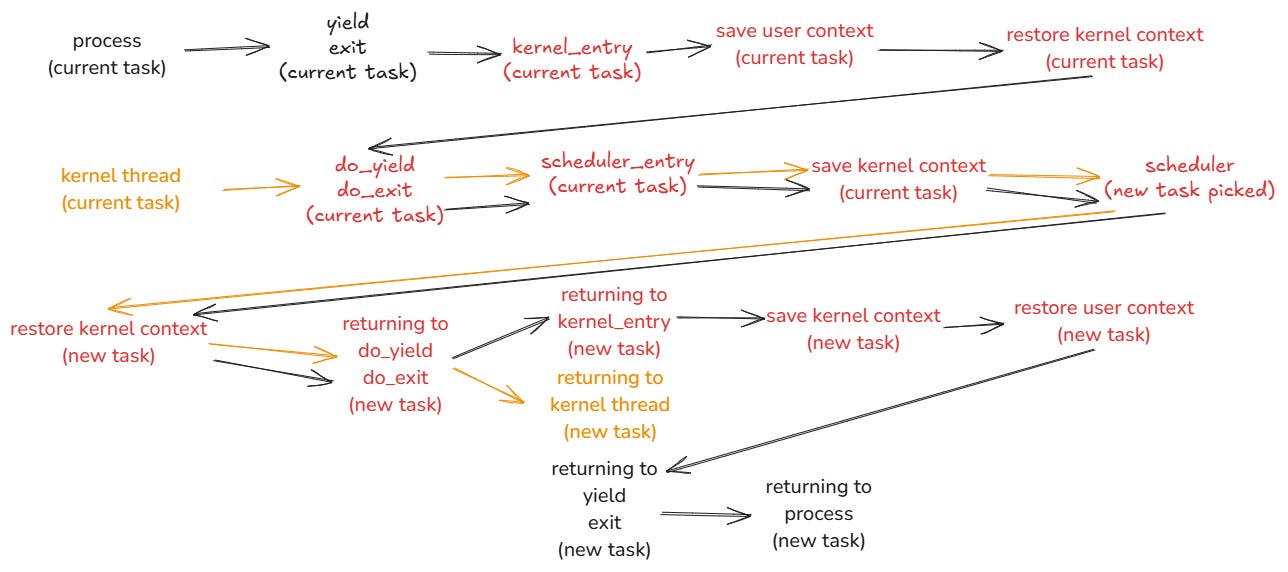
O fluxo preto é de quando um processo de executando, enquanto o laranja é de uma thread de kernel. Ao passar pelo escalonador, uma nova tarefa é escolhida, e pode ser uma thread o kernel ou um processo, seguindo pela mesma ideia das cores. O que está em vermelho são funções/etapas que ocorrem dentro do kernel.
Antes de apresentar a tenebrosa kernel_entry, vamos refletir sobre uma coisa: temos um ponto de entrada único, mas diversos serviços (yield, exit e o que mais surgir). Ao observar novamente o arquivo syslib.cpp:
void yield() { (**kernel_entry_point)(SYSCALL_YIELD); }
void exit() { (**kernel_entry_point)(SYSCALL_EXIT); }Perceba que é a mesma função, o que muda é o argumento dela, o que faz sentido pelo design que estamos analisando. Dentro da função kernel_entry, então, ele deve “selecionar” a função correta de acordo com o parâmetro informado pelo chamador. Se tratarmos esse “parâmetro” como um índice em um vetor de ponteiros para função, nossos problemas estão resolvidos (por enquanto). Assim, eu criei o seguinte vetor no arquivo scheduler.cpp:
void (*syscall_operations[])() = {&do_yield, &do_exit};Pronto, temos um array de ponteiros de função, com as funções que “servimos” ao processo. Se o processo chamar o kernel_entry com o valor 0, ele invocará a do_yield. Se for 1, será do_exit, e assim por diante.
Após muito enrolar, vamos olhar a kernel_entry, que está no arquivo entry.asm. Como eu fiz algumas mudanças na scheduler_entry para parametrizá-la melhor, vou mostrar o arquivo inteiro.
global scheduler_entry, kernel_entry
extern current_task, scheduler, syscall_operations, returning_kernel_entry
%define ESP_OFFSET (3*4)
%define K_REGS_LIMIT (9*4)
%define U_REGS_LIMIT (18*4)
%define ESP_OFFSET_FROM_LIMIT (6*4)
syscall_op dd 0
old_esp dd 0
kernel_entry:
push ebp
mov ebp, esp
mov esp, [current_task]
lea esp, [esp + U_REGS_LIMIT]
pushfd
pushad
mov [esp + ESP_OFFSET], ebp
mov ebx, [ebp+8]
mov [syscall_op], ebx
mov esp, [current_task]
popad
popfd
mov esp, [esp - ESP_OFFSET_FROM_LIMIT]
mov ebx, [syscall_op]
call [syscall_operations + 4*ebx]
returning_kernel_entry:
mov [old_esp], esp
mov esp, [current_task]
lea esp, [esp + K_REGS_LIMIT]
pushfd
pushad
mov ebx, [old_esp]
mov [esp + ESP_OFFSET], ebx
mov esp, [current_task]
lea esp, [esp + K_REGS_LIMIT]
popad
popfd
mov esp, [esp - ESP_OFFSET_FROM_LIMIT]
pop ebp
ret
scheduler_entry:
push ebp
mov ebp, esp
mov esp, [current_task]
lea esp, [esp + K_REGS_LIMIT]
pushfd
pushad
mov [esp + ESP_OFFSET], ebp
mov esp, ebp
call scheduler
mov esp, [current_task]
popad
popfd
mov esp, [esp - ESP_OFFSET_FROM_LIMIT]
pop ebp
retO segredo todo, assim como foi com a scheduler_entry, é posicionar o registrador esp na posição certa do PCB para poder fazer os pushs e pops do lugar certo. A função começa salvando o contexto de usuário:
push ebp
mov ebp, esp
mov esp, [current_task]
lea esp, [esp + U_REGS_LIMIT]
pushfd
pushad
mov [esp + ESP_OFFSET], ebpDepois, como vamos chaver o contexto, precisamos salvar o parâmetro que passaram ao chamar a kernel_entry. Lembra-se que a chamamos passando um argumento, que é o serviço a ser executado? Então. Esse parâmetro está na pilha do contexto do usuário, e como esse contexto vai mudar, já que vamos chaver para o contexto de kernel desse processo, precisamos salvá-lo antes:
mov ebx, [ebp+8]
mov [syscall_op], ebxOk, o parâmetro foi salvo na variável syscall_op. Agora a gente restaura o contexto de kernel do processo:
mov esp, [current_task]
popad
popfd
mov esp, [esp - ESP_OFFSET_FROM_LIMIT]Estamos no contexto do kernel do processo. Só falta chamar o serviço desejado. Basta recuperar o valor de syscall_op e usá-lo como índice no array syscall_operations:
mov ebx, [syscall_op]
call [syscall_operations + 4*ebx]Show de bola! Isso chamará a do_yield e do_exit, que chamará a scheduler_entry… You know the drill. Possivelmente, esse processo será posto pra dormir (mas lembre-se que ele está no contexto de kernel do processo). Quaaaaando esse processo for acordado, ele irá ir retornando das chamadas, e retornando da do_yield (se fosse do_exit, esse processo não retornaria mais, não é mesmo? :D ), ele continuará logo após call [syscall_operations + 4*ebx]. E o que a gente precisa fazer agora?
Bom, todo o serviço do contexto de kernel para esse processo foi feito. Agora, a gente salva esse contexto:
mov [old_esp], esp
mov esp, [current_task]
lea esp, [esp + K_REGS_LIMIT]
pushfd
pushad
mov ebx, [old_esp]
mov [esp + ESP_OFFSET], ebx Perceba que, como precisamos alterar o valor de esp para fazer o procedimento, a gente salva ele provisoriamente em old_esp para salvar o valor correto também.
Depois disso, a gente só restaura o contexto do usuário:
mov esp, [current_task]
lea esp, [esp + K_REGS_LIMIT]
popad
popfd
mov esp, [esp - ESP_OFFSET_FROM_LIMIT]
pop ebp
retE ao fim do código acima, ele já restaura a pilha e retorna para quem chamou yield.
Pera lá um pouquinho! Você acha que me engana? Muito suspeito aquela declaração returning_kernel_entry no meio da função kernel_entry! O que ela faz?
Então jovem, como sempre eu mostrei o caminho feliz. Mas a vida é uma caixinha de surpresas, não é esse algodão-doce que você está pensando ai não! Temos um corner case importante que não tratamos ainda: o primeiro escalonamento para execução do processo.
Pense no seguinte: o PCB do processo está na fila de tarefas prontas. Quando o processo é escolhido pelo escalonador, quem fez isso foi a scheduler_entry, que invoca o scheduler, lembra?
Significa que estamos no contexto de kernel do processo, mas nosso entrypoint está no contexto de usuário! Como pulamos para lá?
Usamos da boa e velha gambiarra! O que fazemos é enganar o processo, e não vamos colocar o entrypoint do processo diretamente para execução, vamos fingir que estamos retornando de uma chamada do sistema, para ele ir restaurando o contexto necessá rerio e acabar no entrypoint do processo mas no contexto de usuário! E pra fazer isso é bem fácil na real (depois que você sabe o que fazer), fazemos uma pequena alteração no método config da classe PCB:
void PCB::config(int pcb_index, void (*entry_point)(), uint32_t pid,
bool kernel_thread) {
this->pid = pid;
this->kernel_thread = kernel_thread;
uint32_t stack = START_STACKS_ADDRESS + 2 * pcb_index * STACK_SIZE;
if (stack > STACK_MAX) {
panic("Stack overflow\n");
}
this->kregs[3] = stack - 8;
this->kregs[2] = *(uint32_t *)(stack - 8) = stack;
*(uint32_t *)(stack - 4) =
kernel_thread ? (uint32_t)entry_point : (uint32_t)&returning_kernel_entry;
...
if (!kernel_thread) {
stack += STACK_SIZE;
if (stack > STACK_MAX) {
panic("Stack overflow\n");
}
this->uregs[3] = stack - 8;
this->uregs[2] = *(uint32_t *)(stack - 8) = stack;
*(uint32_t *)(stack - 4) = (uint32_t)entry_point;
}
this->status = READY;
}Reservamos duas pilhas para o PCB, independente se for uma kernel thread ou processo. Para kernel threads, esse espaço adicional é desperdiçado, mas como são 9 registradores de 4 bytes, estou ok em desperdiçar 36 bytes nesse caso.
Note contudo que fazemos um teste para definir o entrypoint: se for uma thread kernel, nada muda, informamos o entrypoint da thread. Se for um processo, ai informamos o endereço de returning_kernel_entry. Isso porque quando o scheduler_entry terminar, ele vai fazer um ret para esse endereço. O que a returning_kernel_entry faz dali pra frente é restaurar o contexto do usuário e ele vai retornar. Para onde? Agora sim, para o entry_point do processo.
Novamente, usamos o funcionamento de pilhas do x86 para que ele faça o trabalho sujo todo para nós. Ardiloso!
E como ficou o resultado? Olha ai jovem.
E como você já sabe, para conferir o código até esse ponto, visite meu github.