
Apanhando do RDTSC
Porque toda falha é um sucesso, de algum modo...


Antes de iniciar esse post, preciso complementar uma informação que faltou no post anterior. O método de chamada de sistema daquele post se parece muito em como as funções virtuais funcionam em C++. Funções virtuais podem ser sobrecarregadas, significando que o endereço da função original na classe base é alterada pelo novo método. Como isso é resolvido dentro do compilador? Bom, todos os objetos que possuem métodos virtuais possuem uma estrutura chamada VTABLE, que contempla os ponteiros das funções virtuais.
Quando um objeto de classe derivada é construído e atribuído a uma referência da classe base, o compilador troca o endereço da método da classe base para este objeto. O código continua chamando os métodos da classe base, mas o compilador agora tem um ponteiro de ponteiro: ele sabe o endereço da VTABLE desse objeto, que contém um outro ponteiro do método sobrescrito. Por este motivo, esse método de despacho de ponteiros de ponteiro de função se parece com mecanismo usado para syscall aqui. Se você está construindo um compilador que compila códigos orientados a objeto, agora sabe como fazer sobrescrita de métodos.
Por que estou falando disso? Porque está no momento de fazer o crédito extra do P2, que pede:
For extra credit, write a fair scheduler. This means that the scheduler always chooses as the next task to run the one that has had the least amount of time on the CPU thus far. Do not include the time it takes to do a context switch when keeping track of run time thus far. Prove that your scheduler is fair by writing tasks that show execution time on the CPU is fair to within the longest interval between yields.
Então é hora de fazer um escalonador justo, que sempre escolhe os processos que tiveram o menor tempo de CPU a cada rodada. Pra isso a gente precisa saber quanto tempo cada tarefa levou, e o lugar para armazenar essa informação, como você já deve ter deduzido, é no PCB. Tomei a liberdade de medir 4 coisas:
...
class PCB {
...
unsigned long long kernel_cpu_time_last_sched{0};
unsigned long long user_cpu_time_last_sched{0};
unsigned long long total_kernel_cpu_time{0};
unsigned long long total_user_cpu_time{0};Isso para medir o tempo de CPU desde o último escalonamento da tarefa, tanto do kernel no contexto do processo ou para as threads de kernel, quanto o tempo de cpu de usuário, válido apenas para tarefas de usuário (processos).
Fiz assim para evitar que tarefas que estejam executando a muuuuuito tempo, quando outra nova tarefa seja adicionada, esta não fique rodando sozinha até que ela iguale o tempo da tarefa antiga.
Com isso, nosso PCB ganha novos métodos:
void set_kernel_cpu_time(unsigned long long time) {
this->kernel_cpu_time_last_sched += time;
this->total_kernel_cpu_time += time;
};
void set_user_cpu_time(unsigned long long time) {
this->user_cpu_time_last_sched += time;
this->total_user_cpu_time += time;
};
void clear_last_cpu_time() {
this->kernel_cpu_time_last_sched = 0;
this->user_cpu_time_last_sched = 0;
}
unsigned long long get_cpu_time() {
return this->kernel_thread ? this->kernel_cpu_time_last_sched
: this->user_cpu_time_last_sched;
}Os dois primeiros métodos são autoexplicativos, eles incrementam os contadores de tempo locais e globais, do kernel ou do usuário. O terceiro zera o tempo do último escalonamento quando a tarefa é escolhida da fila de tarefas prontas para execução. O último método retorna o tempo de cpu do último escalonamento, diferenciando processos e threads de kernel para que a comparação entre eles seja justa.
Fiz uma pequena alteração na classe Scheduler:
class Scheduler {
...
public:
virtual void sched(QueueNode<PCB> *);
...
};Você pode ver que transformei o método sched em virtual, para poder criar uma nova classe derivada:
class FairScheduler : public Scheduler {
public:
void sched(QueueNode<PCB> *);
};Afinal, nosso objetivo é única e exclusivamente alterar o método sched, para que ele passe a considerar o tempo de execução da tarefa.
Agora, para declarar o escalonador, basta fazermos assim:
FairScheduler fairSched;
Scheduler *sched = &fairSched;que o restante do código fica todo intacto! God bless the OOP! E isso se liga ao assunto da VTABLE e tabela de despacho da abertura desse post.
Acabou? Logicamente que não, criança. Vamos ver o que o método sched dessa nova classe faz.
void FairScheduler::sched(QueueNode<PCB> *task) {
...
queue_insert_ordered(this->ready_queue, task, &comparePCB);
...
}Só isso, o resto é código pra ajudar a debugar (você logo vai entender o motivo). Quem faz todo o trabalho sujo é a função queue_insert_ordered. Vamos a ela:
template <class T>
void queue_insert_ordered(QueueNode<T> *&queue, QueueNode<T> *node,
int (*compare)(T *, T *)) {
if (queue == nullptr) {
queue = node;
return;
}
QueueNode<T> *tmp = queue;
while (tmp != queue->previous) {
if (compare(&node->get(), &tmp->get()) < 0) {
break;
}
tmp = tmp->next;
}
if (compare(&node->get(), &tmp->get()) < 0) {
tmp = tmp->previous;
}
tmp->next->previous = node;
node->next = tmp->next;
tmp->next = node;
node->previous = tmp;
if (compare(&node->get(), &queue->get()) < 0) {
queue = node;
}
}Ele é muito parecido com o queue_insert, a diferença é que ele uma uma função de comparação para saber onde inserir o novo elemento. A função é genérica de propósito, afinal, estamos usando templates, e o usuário que a invocar deve passar essa função de comparação como argumento. Na chamada da função, você perceberá que eu passei o endereço de comparePCB. Aqui está essa função:
static int comparePCB(PCB *a, PCB *b) {
...
if (a->get_cpu_time() < b->get_cpu_time()) {
return -1;
} else if (a->get_cpu_time() > b->get_cpu_time()) {
return 1;
} else {
return 0;
}
}Não é muito diferente das funções compareTo do Javinha.
E como medimos o tempo? A gente cria uma variável de tempo corrente, e funções para iniciar e parar um timer:
unsigned long long curr_time = 0;
...
extern "C" void start_timer() {
curr_time = get_timer();
...
}
extern "C" void stop_kernel_timer() {
unsigned long long tmp = get_timer();
unsigned long long diff = tmp - curr_time;
...
current_task->get().set_kernel_cpu_time(diff);
curr_time = tmp;
...
}
extern "C" void stop_user_timer() {
unsigned long long tmp = get_timer();
unsigned long long diff = tmp - curr_time;
current_task->get().set_user_cpu_time(diff);
curr_time = tmp;
...
}Onde essas funções são chamadas? Nas trocas de contexto (de usuário ou kernel):
...
extern current_task, scheduler, syscall_operations, returning_kernel_entry, start_timer, stop_kernel_timer, stop_user_timer
...
kernel_entry:
...
call stop_user_timer
...
call start_timer
mov ebx, [syscall_op]
call [syscall_operations + 4*ebx]
returning_kernel_entry:
call stop_kernel_timer
...
call start_timer
...
ret
scheduler_entry:
...
call stop_kernel_timer
...
call scheduler
...
call start_timer
...
retBasicamente, paramos e iniciamos os timers dentro dessas funções acima. Um pouco antes de liberar a cpu para a próxima tarefa, também, paramos o timer para que a função sched possa usar o tempo nas comparações.
void do_yield() {
stop_kernel_timer();
current_task->get().ready();
sched->sched(current_task);
start_timer();
scheduler_entry();
} Por fim, quando uma nova tarefa é escalonada, o escalonador limpa os valores prévios:
extern "C" void scheduler() {
sched->inc_count();
current_task = sched->get_ready_task();
current_task->get().clear_last_cpu_time();
current_task->get().run();
}Há outras pequenas atividades que devem ser feitas, que é instanciar o template para usar o PCB, e fazemos isso no arquivo queue-impl-pcb.cpp:
template void queue_insert_ordered(QueueNode<PCB> *&, QueueNode<PCB> *,
int (*)(PCB *, PCB *));Esse tipo de coisa eu não mais farei nos próximos posts, pois é repetitivo. Só se aparecer algo muito diferente que valha a pena mencionar.
Isso tudo que foi dito até aqui é suficiente para fazer esse escalonador justo, considerando os tempos de execução das tarefas. Só faltou um pequeno detalhe: a função get_timer, invocada pelas funções start_timer, stop_kernel_timer e stop_user_timer acima.
Começando o pesadelo
Retomando a descrição do P2:
The function util.c:get_timer() returns the number of instructions that have been executed since boot.
Só isso? Oxi, tá fácil hein. Que instrução x86 faz isso? A RDTSC:
Reads the current value of the processor’s time-stamp counter (a 64-bit MSR) into the EDX:EAX registers. The EDX register is loaded with the high-order 32 bits of the MSR and the EAX register is loaded with the low-order 32 bits. (On processors that support the Intel 64 architecture, the high-order 32 bits of each of RAX and RDX are cleared.)
The processor monotonically increments the time-stamp counter MSR every clock cycle and resets it to 0 whenever the processor is reset. See “Time Stamp Counter” in Chapter 18 of the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3B, for specific details of the time stamp counter behavior.
Quando mexi com esse trabalho, em 2020, essa parte do código já estava pronto. Confesso que nem me preocupei em como isso era feito. Lembre-se que esses trabalhos são acadêmicos, com o intuito de exercitar conceitos bem específicos. Mexer com temporização no x86 não era um desses conceitos, e vinha pronto no código fornecido para nós.
Então, chumbei a instrução rdtsc na minha função get_timer. Note também que os códigos que usam essa função já retornam para variáveis unsigned long long. A instrução rdtsc coloca os valores nos registradores edx:eax, mas o compilador é inteligente o suficiente para trabalhar bem com esses valores de 64bit. Então tudo certo!
Será mesmo? Bom, quando comecei a mexer com essa parte, os valores que retornavam eram malucos. Pior, quando chamava a rdtsc na sequência, na vã esperança de retornar valores compatíveis, minha sanidade começou a esvair pelo ralo.
A partir de agora, o que virá é um relato de várias tentativas para tentar entender o que estava acontecendo. Não consigo afirmar com certeza qual alteração foi efetiva, ou mesmo se alguma outra coisa deveria ter sido feita. Mas pelo menos cheguei em uma resposta “plausível”. Vamos lá.
Sistema de virtualização
Começo o primeiro post (VEJA AQUI) avisando que não usaria o emulador Bochs, mas sim o QEMU. Mais do que isso, rodo o QEMU direto no meu Ubuntu, que roda no meu WSL2 no meu Windows 11. Percebe onde quero chegar?
Estávamos chamando o QEMU assim:
/usr/bin/qemu-system-i386 -machine accel=kvm ... -cpu host ...Isso estava fazendo o QEMU rodar direto na CPU virtualizado pelo KVM, usando como CPU o processador do meu host. Isso significa que ele estava pegando os valores do timestamp do meu CPU, que está rodando diversas outras coisas, como o próprio QEMU, VSCode, WSL, Windows, Red Dead Redemp…. ops, esse não. Pior, os valores não eram consistentes entre as chamadas, pois é provável que o processo do QEMU esteja executando em CPUs diferentes, que possuem timestamps diferentes.
Então, a primeira alteração foi alterar o método de aceleração para uma emulação embutida no QEMU, e dizer que estamos usando apenas uma CPU:
/usr/bin/qemu-system-i386 -smp cpus=1 -machine accel=tcg ...Resolvido? Não. Volte um pouco e veja a citação do P2, que diz que a get_timer retorna o número de instruções que foram executadas desde o boot. Só que os números que a rdtsc continuavam não fazendo sentido. Ao executar duas rdtsc na sequência, deveria vir apenas 1 de diferença para o valor anterior. Ok, 2, 3, no máximo 5 instruções, considerando uma arquitetura superescalar em que há pipelines e execuções fora de ordem, mas não deveria ser muito diferente disso. O problema é que o valor retornado girava na casa de 70 mil!
Diferenças de TSC entre processadores
Se você for na página da wikipedia sobre as instruções x86 encontrará o seguinte:

Então, antigamente o TSC era incrementado de 1 mesmo, o que era previsto pelo trabalho. Mas agora, processadores mais modernos não são mais assim. Mais do que isso, aquela nota de rodapé [m] da imagem acima diz:

Bom, diante disso, assumi que o valor era incrementado, e de alguma forma era proporcional ao número de instruções executadas, mesmo sem saber exatamente quando. E ai começou o segundo problema.
O compilador também não colabora!
Observe o código abaixo:
void thread1() {
int x = 0;
for (int i = 0; i < 10000; i++) {
x += i * 2;
}
printk("t1 10000 x=%d\n", x);
printk("t1 sleeping 10 second\n");
do_yield();
printk("t1 exiting\n");
do_exit();
}Meu objetivo ai em cima é só fazer o processador gastar tempo calculando nada. Outras threads tinham um código parecido, mas variando o valor de i. Ao executar o código, as threads levavam quase o mesmo tempo, independente do valor do laço for. Era hora de invocar o gdb e verificar o que estava acontecendo.
O problema é que o compilar é muito mais inteligente que eu (não é muito difícil, mas enfim). O compilador vê um código desse e pensa: “poxa, mas eu consigo calcular isso ai de antemão, o código dele não precisa iterar nesse laço NEM UMA ÚNICA VEZ!". E ele está certo. Só que agora eu não quero eficiência e otimização, eu estou testando a temporização das threads, caraca! Bom, isso nem é tão difícil assim de resolver, basta enfiar um volatile (volatile int x = 0;) que o compilador é forçado a ler o valor da memória e assim, iterar no loop. Percebe-se que coisas difíceis não são fáceis.
Mesmo corrigindo o código acima, a execução não estava satisfatória. Precisei apelar: até o momento, eu não havia consultado nenhuma vez o código original. Mas estava chegando em um beco sem saída. Afinal, o que o código original que eu tinha acesso faz?1

E o meu código estava assim (arquivo util.h):
#include <x86intrin.h>
...
inline unsigned long long get_timer() {
...
return __rdtsc();
};A tradução dos dois códigos resulta na mesma coisa, a instrução rdtsc em x86. Aproveitei e vi a função delay do arquivo deles:

E o que é esse MHZ ai?

Ahá, tem um valor chumbado no código. Eles prepararam esse código para as máquinas do laboratório fishbowl de Princeton. Esse valor não bate com nosso ambiente de desenvolvimento.
Nesse momento, eu troquei aquele código de loop e copiei essa função de delay. E fiquei testando valores de MHZ para ver se conseguia gerar um delay de uns 10 segundos.
Quando não obtive sucesso, o próximo passo foi apelar.
Usando o Bochs
Cansado de apanhar da vida e de todos, resolvi usar o Bochs para comparar as diferenças entre os dois. Primeiro, instalei o Bochs via apt-get:
sudo apt-get install bochs bochsbios vgabios bochs-xNa minha distro, ele instalou a versão 2.7 do Bochs.
Depois, criei o arquivo ./util/bochsrc abaixo.
megs: 16
#needs package bochsbios
romimage: file=/usr/share/bochs/BIOS-bochs-legacy
#needs package vgabios
vgaromimage: file=/usr/share/bochs/VGABIOS-lgpl-latest
vga: extension=vbe
floppya: 1_44=./build/boringos.img, status=inserted
boot: floppy
log: /tmp/bochsout.txt
mouse: enabled=0
cpu: count=1, ips=1000000, reset_on_triple_fault=1
#vga_update_interval: 150000
#i440fxsupport: enabled=1
#needs package bochs-x
display_library: x
log: /dev/null
magic_break: enabled=1
Agora, basta comentar a linha que chama o QEMU para chamar o Bochs:
#!/bin/sh -ex
...
CURRDIR=`pwd`
#/usr/bin/qemu-system-i386 ...
bochs -q -f $CURRDIR/util/bochsrcAo executar o arquivo ./util/VM_BoringOS.sh, recebi o erro bx_dbg_read_linear: physical memory read error (phy=0x000100000000, lin=0x0000000100000000). Os endereços de memória não eram esses, mas o erro era. Depois de muito pesquisar, a sugestão foi instalar a versão 2.8. Ough. Lá vai:
wget https://github.com/bochs-emu/Bochs/archive/refs/tags/REL_2_8_FINAL.tar.gz
mv REL_2_8_FINAL.tar.gz bochs_2_8.tar.gz
tar -zxvf bochs_2_8.tar.gz
cd Bochs-REL_2_8_FINAL/bochs/
./configure --with-all-libs -enable-plugins --enable-debugger --enable-smp --enable-x86-debugger
make
sudo make installNo fim das contas, consegui executar meu kernel no Bochs. De cara descobri que:
A diferença entre dois timestamps do rdtsc gira em torno de 3, 4 ou 5 instruções
Havia um erro no meu código do delay, estava
unsigned long long deadline = millis * 1000 * MHZ;quando deveria serunsigned long long deadline = get_timer() + (millis * 1000 * MHZ);.
Com essas constatações e correções, planejei o seguinte código para testes do escalonador justo. O arquivo tasks.cpp:
...
void thread1() {
printk("t1 sleeping 10 second\n");
delay(10000);
do_yield();
printk("t1 exiting\n");
do_exit();
}
void thread2() {
printk("t2 sleeping 1 second\n");
delay(1000);
do_yield();
printk("t2 exiting\n");
do_exit();
}
void thread3() {
printk("t3 sleeping 4 second\n");
delay(4000);
do_yield();
printk("t3 exiting\n");
do_exit();
}
void thread4() {
printk("t4 sleeping 2 second\n");
delay(2000);
do_yield();
printk("t4 exiting\n");
do_exit();
}E o process1.cpp:
...
int main() {
set_display_position(20, 0);
printk("p1 sleeping 0.5 second\n");
delay(500);
yield();
printk("p1 exiting\n");
return 0;
}Os processos são adicionados na ordem listada, então a thread1 é o PID 0, thread2 é o PID 1, até o processo 1 que tem PID 4. Todos começam com tempo de cpu 0, que vai mudando conforme a tarefa vai fazendo yield e vai sendo reinserida na lista de tarefas prontas. A ordem de execução dos PIDs deve ser então: 0, 1, 2, 3, 4, (neste momento, todas as tarefas já executaram um pouco e foram reinseridas na fila), 4, 1, 3, 2, 0. A cada reinserção da tarefa na fila, para debugar, pedi para imprimir o nó, com o PID e seu tempo de cpu. E, voilá, é isso que temos:
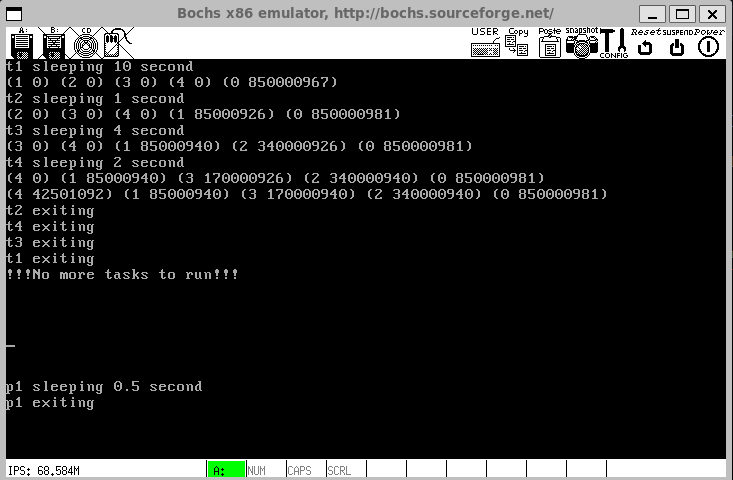
Perfeito. Depois disso, fiquei ajustando o valor do MHZ e cronometrando a execução. Como é esperado que t1 execute por 10 segundos, cheguei no valor de 85 MHZ para o Bochs.
Executando o mesmo código no QEMU, com esse mesmo valor de 85 MHZ, o resultado em termos de valores apresentados são muito próximos no quesito ordem de grandeza, confira:

Mas a execução é quase imediata, t1 não leva 10 segundos. Tentei alterar o MHZ e cronometrar, mas a tarefa foi infrutífera. Além de não conseguir chegar a um valor factível, por algum motivo a ordem das tarefas foi alterada, o que não faz sentido. Parece que para o QEMU, ainda falta configurações que eu ainda não estou ciente. Faz parte, não dá pra ganhar todas.
Como de praxe, o código para esta parte do nosso trabalho está no meu github.
No fringir dos ovos…
A gente acabou esse post com mais perguntas do que respostas. Mas é assim que a gente aprende no fim das contas. Se você não acredita no tamanho da encrenca dessa instrução rdtsc, veja essa galera do SUSE analisando isolamento de CPU no kernel do Linux.
Mas chega de P2! Nos próximos posts vamos começar o P3 e nosso kernel preemptivo! Minha esperança é que usando o PIT nós consigamos detectar a velocidade da CPU, talvez usando o HPET. Mas não conte com isso, não prometo nada :D
Eu possuo o código original. Contudo, esse código foi feito pela universidade de Princeton, sem permissão de distribuição. Não tenho permissão para apresentar o código aqui, eles são bem rigorosos com plagiarismo. A página do projeto tem alguns contatos, você pode tentar a sorte se quiser obter tal código por vias regulares.