
O problema Inception da troca de contexto
Ou: como trocar o motor com o carro andando


A demora do último post para este não foi em vão. Neste post, seguindo o P2, começaremos a mexer com troca de contexto de tarefas. Ainda estamos em nível de threads do kernel, portanto nada de syscall ainda, mas a demora vem justamente da dificuldade em fazer algo que em teoria é simples mas que na prática é diferente da teoria.
Já ouviu falar do ovo de Colombo? Existe uma história que Colombo (aquele mesmo) apostava se alguém conseguia colocar um ovo em pé. Na negativa de todos, para os incautos que se atreviam apostar contra, estes se deparavam com o Colombo quebrando um pedaço da base do ovo, permitindo que ele assim ficasse em pé. Nisso, obviamente todos falavam “Ah, mas se fosse pra fazer assim, eu fazia!”. Pois é, e não fez por que, cara pálida?
Enfim, aqui acontece a mesma coisa. Depois que você ver a solução, você vai ficar com cara de trouxa, com todo respeito aos trouxas, amo muito todos eles. E você pode até pensar “Hum, eu faria fácil isso (ou talvez até melhor)”. Longe de duvidar de você, mas há muitas formas de resolver isso, e se você tentar procurar alguma solução na internet, pouco provável que tenha alguma que seja aderente à narrativa proposta pelo P2. Soluções da internet em geral trabalham com TSS e troca de contexto em nível de hardware, que ainda não estamos usando. Sem conhecer a solução por completo, soluções parciais talvez não sejam tão fáceis de se adaptar para nosso contexto.
Duvida? Tente partir do P2 e do nosso último código e tente fazer uma troca de contexto sozinho. Eu fiz esse trabalho em 2020, com várias partes do código já feita pelos professores, nós precisaríamos completar o código pré-existente. Ainda assim, sem consultar esse código original, demorou um tempo para eu fazer funcionar.
E se você já teve (e você deve ter tido) contato com o básico de sistemas operacionais, já deve ter ouvido falar de troca de contexto: quando uma tarefa é interrompida, devemos salvar o “estado” dessa tarefa para retomar do ponto interrompido posteriormente. N arquitetura x86, por estamos estamos nos referindo aos registradores (incluindo o importantíssimo registrador EFLAGS). O problema é que, tal qual o Inception, precisamos executar instruções no processador para salvar tais registradores. Percebe onde quero chegar? É quase como trocar o motor de um avião com ele voando.
Bem, quase isso. Obviamente se este post está sendo escrito, significa que há como fazer isso. Tal qual Jack, vamos por partes.
Antes de adentrarmos nos meandros, o P2 diz isso na seção de Hints:
One of the first things you will need to do is to implement a queue data structure. gdb is a much nicer environment than bochs in which to debug, so we strongly recommend you that you test your data structure code in user-space first.
Então, vamos fazer nossa fila. A fila será útil para várias coisas (várias mesmo), mas para nosso momento, teremos uma fila de tarefas “prontas” e toda vez que precisarmos escolher a próxima tarefa que será executada pelo processador, recorreremos a essa fila.
Obs: falamos bastante de pilha até esse momento, e agora fila. Se não ficou claro, estruturas de dados são muito importantes em Ciência da Computação e agregados, e no desenvolvimento de Sistemas Operacionais isso não é diferente. Não entrarei nos detalhes de tais implementações, sugiro que você chegue neste ponto com tais conceitos dominados.
O arquivo queue.h (final_revisado_v2_AGORA_VAI.txt) está assim:
#ifndef __QUEUE_H
#define __QUEUE_H
namespace Datastructure {
template <class T> class QueueNode {
public:
T data;
QueueNode<T> *next, *previous;
constexpr QueueNode<T>() : next(this), previous(this){};
constexpr explicit QueueNode<T>(T data)
: data(data), next(this), previous(this){};
void insert(QueueNode<T> *);
QueueNode<T> *remove(QueueNode<T> *);
void print();
constexpr T &get() { return data; }
};
} // namespace Datastructure
#endifAqui, algumas observações. Não tenho acesso aos operadores new ou delete (tampouco malloc e free), pois não temos stdlib. Tais estruturas já estarão pré-alocadas em algum lugar quando esses ponteiros forem usados.
Outro ponto de atenção é que estou usando templates, notou? Isso porque já sei que usarei tal estrutura em várias situações futuras. E para o momento, testei com o tipo int e com a estrutura PCB, local onde armazenarei o estado do processo e detalharei melhor posteriormente.
Note que isso é uma lista circular duplamente ligada. Quando o nó é criado, os ponteiros next e previous apontam para o próprio nó (this). Temos as opções de insert (insere no fim da fila) e remove (retira do início), como de costume. O método get retorna a referência para o dado em si. Há também o método auxiliar print, para debug, que percorre a lista e vai imprimindo os elementos.
A implementação dos métodos fica no arquivo queue.cpp, e se você já implementou uma fila duplamente ligada, já deve ter feito algo similar:
#include "include/queue.h"
#include "include/kernel.h"
#include "include/util.h"
using namespace Datastructure;
template <class T> void QueueNode<T>::insert(QueueNode<T> *node) {
this->previous->next = node;
node->previous = this->previous;
this->previous = node;
node->next = this;
...
}
template <class T> QueueNode<T> *QueueNode<T>::remove(QueueNode<T> *node) {
if (this == node && this->next == this) {
...
return nullptr;
}
QueueNode<T> *tmp = this->next;
node->previous->next = node->next;
node->next->previous = node->previous;
...
return this == node ? tmp : this;
}
template <class T> void QueueNode<T>::print() {
QueueNode<T> *tmp = this;
do {
Util::printk("%d ", tmp->data);
tmp = tmp->next;
} while (tmp != this);
Util::printk("\n");
}Os … só omitem códigos comentados, que coloquei para fazer debug. Se quiser ver o que tem nesses trechos, vá até o meu github.
E aqui começou os meus problemas. O fato de usar templates e C++ sem ter domínio me fez encarar problemas dos mais variados quando instanciando os tipos QueueNode<int> e QueueNode<PCB>, com o linker reclamando mais que filhote de passarinho com fome.
Graças ao meu bom e velho amigo Dr. Renan Marks, professor da UFMS (visite o site dele: https://renanmarks.net/), o mesmo me enviou uma entrada no StackOverflow que resolveu o meu problema: eu deveria instruir o compilador e mostrar as implementações dos templates para cada tipo específico. Por este motivo sórdido, temos dois arquivos de implementações, queue-impl-int.cpp e queue-impl-pcb.cpp, que no fim das contas são praticamente iguais.
#include "queue.cpp"
template void Datastructure::QueueNode<int>::print();
template void
Datastructure::QueueNode<int>::insert(Datastructure::QueueNode<int> *);
template Datastructure::QueueNode<int> *
Datastructure::QueueNode<int>::remove(Datastructure::QueueNode<int> *);#include "queue.cpp"
template void Datastructure::QueueNode<PCB>::print();
template void
Datastructure::QueueNode<PCB>::insert(Datastructure::QueueNode<PCB> *);
template Datastructure::QueueNode<PCB> *
Datastructure::QueueNode<PCB>::remove(Datastructure::QueueNode<PCB> *);Nesse caso, tais arquivos “incluem” o arquivo .cpp. Estranho né? Também achei. Agora, em vez de adicionarmos o arquivo objeto queue.o, adicionamos os arquivos objetos das implementações diretamente, queue-impl-int.o e queue-impl-pcb.o.
Com a fila, templates e C++ superados, vamos para a próxima etapa. Estamos trabalhando com um kernel não preemptivo. Isso significa que as tarefas precisam explicitamente informar que concedem o processador, possivelmente para colaborar com outras tarefas. Elas também podem encerrar a execução. Embora isso seja impensável em um sistema operacional moderno, onde cada tarefa, tal qual o Quico, acha que o processador é só seu e tem toda a memória a sua disposição, aqui vamos em uma abordagem mais simples. Calma que no futuro isso mudará. Por enquanto, assuma as premissas que estou colocando aqui.
Esses slides do P2 mostram bem como é o comportamento das aplicações dessa forma:

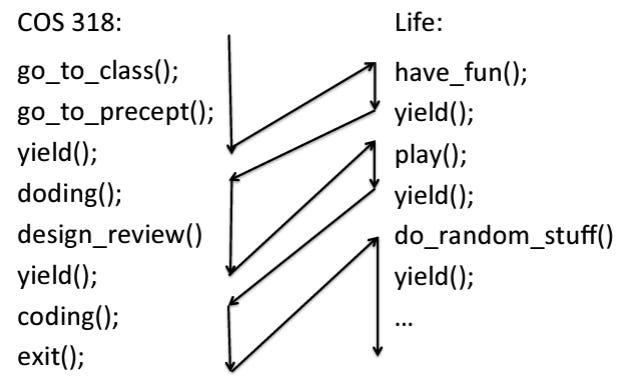
Pelas imagens acima, perceba que as tarefas precisam conceder o processador (invocar a função yield). Quando elas encerram, elas chamam a função exit. Para as tarefas de kernel, chamamos as tarefas do_yield e do_exit.
No nosso caso, as tarefas estão no arquivo tasks.cpp, listadas abaixo.
#include "include/tasks.h"
#include "include/kernel.h"
#include "include/screen.h"
#include "include/util.h"
void thread1() {
Screen::set_pos(0, 0);
Screen::set_colors(Screen::BLACK, Screen::WHITE);
Util::printk("Thread 1\n");
unsigned int i = 0;
while (i < 20000) {
Util::printk(" ");
Screen::carriage_return();
Util::printk("%d", i++);
do_yield();
}
Util::printk("\nThread 1 exited!\n");
do_exit();
}
void thread2() {
Screen::set_pos(13, 0);
Screen::set_colors(Screen::WHITE, Screen::BLACK);
Util::printk("Thread 2\n");
unsigned int i = 0;
while (i < 10000) {
Util::printk(" ");
Screen::carriage_return();
Util::printk("%d", i++);
do_yield();
}
Util::printk("\nThread 2 exited!\n");
do_exit();
}As tarefas são simples, apenas para ver o funcionamento da troca de contexto. Cada tarefa entra em um loop, imprimindo um contador. Quando o contador atinge um determinado valor, o loop é encerrado e a tarefa informa que terminou. Os contadores são propositalmente assimétricos, para notarmos quando uma tarefa encerra e a outra não, e quando ambas terminam. Isso é útil para validarmos a fila e a troca de contexto de forma correta (o que deve ocorrer se não há mais tarefas a serem executadas?).
Bom, quando as tarefas forem interrompidas, onde armazenaremos o estado da tarefa? A resposta já foi dita acima, e na estrutura conhecida como PCB, ou Process Control Block. Vamos analisá-lo.
#ifndef __KERNEL_H
#define __KERNEL_H
#include "queue.h"
#include "screen.h"
#include "util.h"
#include <cstdint>
#define NUM_TASKS 2
#define STACK_SIZE 0x1000
#define START_STACKS_ADDRESS 0x41000
enum TASK_STATUS { READY, RUNNING, EXITED };
class PCB {
uint32_t regs[9]; // EDI, ESI, EBP, original ESP, EBX, EDX, ECX, EAX, EFLAGS
uint32_t pid;
TASK_STATUS status;
bool kernel_thread;
int display_position = 0;
char current_color;
public:
void exit() { status = EXITED; };
bool is_exited() { return status == EXITED; };
void ready() { status = READY; };
void run() { status = RUNNING; };
void config(void (*)(), uint32_t, uint32_t, bool);
[[nodiscard]] constexpr int get_display_position() {
return display_position;
};
constexpr void set_display_position(int pos) { this->display_position = pos; }
constexpr void set_display_color(Screen::Colors foreground,
Screen::Colors background) {
this->current_color = (foreground & 0x0f) | (background << 4);
}
[[nodiscard]] constexpr char get_display_color() {
return this->current_color;
};
...
PCB() {
this->status = EXITED;
this->kernel_thread = false;
this->display_position = 0;
this->set_display_color(Screen::GRAY, Screen::BLACK);
};
};O primeiro ponto importantíssimo é que o primeiro membro da classe NÃO PODE SER ALTERADO. Estou falando no uint32_t regs[9]. Esse vetor guardará o estado dos registradores, e o código que faz isso manipula um ponteiro para PCB e vai tentar fazer isso nesse endereço específico, e com deslocamento esperado do início da estrutura/classe. Os demais membros não tem grandes mistérios. Temos um identificador do processo (pid), o estado da tarefa (para controle do escalonador), se essa tarefa é do kernel ou do usuário. Por fim, cada tarefa armazenará sua própria posição e cores para impressão da printk.
Dos métodos de manipulação do PCB, perceba que vários tratam do estado da tarefa ou de manipulação de posições e cores do display. O que destoa dos demais é justamente o mais importante: config. Vamos ver a cadeia de chamadas para entender o que é feito, pois aqui o negócio começa a complicar. O arquivo principal, kernel.cpp adiciona as tarefas.
sched.add_task(&thread1, true);
sched.add_task(&thread2, true);sched é um objeto do tipo Scheduler que iremos detalhar depois, mas entraremos nessa função add_task, pois isso é importante agora (arquivo scheduler.cpp).
void Scheduler::add_task(void (*entry_point)(), bool kernel_thread) {
int i = 0;
while (i < NUM_TASKS) {
if (this->pcbs[i].get().is_exited()) {
break;
}
i++;
}
if (i >= NUM_TASKS) {
Util::panic("No more PCB available\n");
}
this->pcbs[i].get().config(entry_point, this->current_stack_address,
this->current_pid++, kernel_thread);
this->current_stack_address += STACK_SIZE;
if (this->ready_queue == nullptr) {
this->ready_queue = &this->pcbs[i];
} else {
this->ready_queue->insert(&this->pcbs[i]);
}
}O objeto sched possui um array de PCB. Para adicionar uma nova tarefa, precisamos percorrer o vetor e verificar que entrada não está sendo usada (ou seja, a tarefa já terminou, e seu estado é EXITED). Note, isso NÃO é a fila de tarefas prontas, são coisas diferentes! Esse vetor é estático, e se as tarefas encerram de forma aleatória, precisamos encontrar as entradas desocupadas.
Se o vetor for todo percorrido e uma entrada adequada for encontrada, o kernel entra em pânico e congela. Caso contrário, adicionaremos essa tarefa nessa entrada vaga do vetor de PCB. Então:
this->pcbs[i].get().config(entry_point, this->current_stack_address,
this->current_pid++, kernel_thread);O trecho acima solicita a configuração da nova tarefa, no entry_point determinado (nos exemplos, foi &thread1 e &thread2). O escalonador mantém um controle das pilhas usadas, e informa isso nessa chamada. Os slides mostram onde devemos colocá-las (a partir do endereço 0x40000, cada pilha com tamanho de 4KB ou 0x1000 bytes).

O escalonador mantém ainda um controle do contador de pid para novas tarefas. Quem chamou o método add_task deve informar se essa tarefa é uma tarefa de kernel ou do usuário (kernel_thread). No nosso exemplo, tanto a thread1 quanto a thread2 são threads de kernel.
E o que esse método config faz? Vamos analisá-lo.
void PCB::config(void (*entry_point)(), uint32_t stack, uint32_t pid,
bool kernel_thread) {
this->pid = pid;
this->regs[3] = stack - 8;
this->regs[2] = *(uint32_t *)(stack - 8) = stack;
*(uint32_t *)(stack - 4) = (uint32_t)entry_point;
this->kernel_thread = kernel_thread;
this->status = READY;
}Acredito não haver mistério para os campos pid, kernel_thread e status, certo? Mas o que está acontecendo nas linhas intermediárias? Aqui começa a beleza da coisa. Vamos trabalhar com exemplos? suponha que o entry_point seja 0x1720 e a pilha seja 0x40000. O quarto registrador (regs[3]) recebe o valor 0x3FFF8 (stack - 8). O terceiro registrador (regs[2]) e o endereço apontado por 0x3FFF8 recebem o valor da pilha (0x40000). O endereço apontado pelo endereço 0x3FFFC recebe o entry point, ou seja, 0x1720. Mas afinal, pra quê isso? Bom, eu ainda não falei, mas o regs[3] é o esp e o regs[2] é o ebp. Isso porque a função que usaremos para empilhar os registradores é a pushad, que empilha os registradores em uma ordem específica1. Quando esses dados forem carregados do estado salvo (isso que estamos preenchendo agora) para os registradores, a ideia é que eles e a memória estejam conforme a imagem abaixo.

O truque aqui é que o escalonador, quando selecionar essa tarefa para execução (lembre-se que é a primeira vez dela) recarregará o estado, mas ele continuará a execução como se nada tivesse acontecido até terminar o escopo de sua função. Ao final, ele restaurará o registro de ativação como já bem sabemos: pop ebp, ret. Nós então, malandramente, posicionamos o ponteiro do topo da pilha para o endereço onde essas ações irão acontecer. Quando pop ebp for executado, esp ficará com o valor 0x3FFC e ebp receberá o valor do a instrução pop, que pela imagem no nosso exemplo, é 0x40000. Depois, a instrução ret é executada e ela faz um pop mas para o registrador eip! Nesse ponto, temos os registradores ebp e esp apontando para o mesmo lugar (0x40000) e eip possui agora o entry point da tarefa. A tarefa agora executará normalmente: push ebp/mov ebp, esp/etc. Pronto! Para a primeira tarefa, já temos o fluxo de execução. E se você foi atento (e eu espero que tenha sido), notou que não armazenamos o endereço do entry point no PCB em momento nenhum! Nós só utilizamos os mecanismos da arquitetura x86 contra ela mesma. Esse tipo de estratégia garantia a consistência da pilha entre as chamadas.
Mas e para as tarefas em andamento? Como salvamos a tarefa em execução e recuperamos uma que esteja pronta? Bom, para isso criei a classe Scheduler abaixo no arquivo kernel.h.
class Scheduler {
Datastructure::QueueNode<PCB> pcbs[NUM_TASKS];
Datastructure::QueueNode<PCB> *ready_queue;
uint32_t current_pid{0};
uint32_t scheduler_count{0};
uint32_t current_stack_address{START_STACKS_ADDRESS};
public:
void resched(Datastructure::QueueNode<PCB> *);
void inc_count() { this->scheduler_count++; };
Datastructure::QueueNode<PCB> *get_ready_task();
void add_task(void (*)(), bool);
};O escalonador possui aquele vetor de PCB dito anteriormente, bem como a fila de tarefas prontas. Ele mantém aquelas informações de PID atual, contagem de escalonamentos e o endereço da pilha válido para a próxima nova tarefa que for criada.
Como métodos, já tratamos do add_task. inc_count acredito que também dispensa comentários. Vamos olhar os outros dois que faltam, começando com get_ready_task.
Datastructure::QueueNode<PCB> *Scheduler::get_ready_task() {
if (this->ready_queue == nullptr) {
Util::printk("!!!No more tasks to run!!!\n");
while (true) {
/*NO TASKS TO RUN - BUSY WAIT*/
}
} else {
Datastructure::QueueNode<PCB> *tmp = ready_queue;
this->ready_queue = ready_queue->remove(tmp);
...
return tmp;
}
}Essa função apenas remove primeiro elemento da fila. O que ela faz de diferente é que se não houver mais tarefas aptas para execução, ele fica em um loop infinito, afinal, não há o que executar.
O método resched é apresentado abaixo.
void Scheduler::resched(Datastructure::QueueNode<PCB> *task) {
if (this->ready_queue != nullptr) {
this->ready_queue->insert(task);
} else {
this->ready_queue = task;
...
}
}Aqui, a mesma coisa. Se a fila estiver vazia, a tarefa que deve ser reescalonada vira a primeira. Caso contrário, ela é inserida no fim da fila.
Mas em que momento o escalonador é invocado? Pois é, ainda não mostramos isso. Nossa premissa de kernel não preemptivo implica que ou a tarefa concede a CPU ou ela termina sua execução. Nos dois casos, o escalonador é invocado e é feito nas funções do_yield e do_exit, no arquivo scheduler.cpp.
void do_yield() {
current_task->get().ready();
sched.resched(current_task);
scheduler_entry();
}
void do_exit() {
current_task->get().exit();
scheduler_entry();
}São as funções mais bestas do universo. A primeira, do_yield, coloca a tarefa em execução do status RUNNING para READY. Ele então reescalona e tarefa e chama a função scheduler_entry. Suspeito.
Já para a função do_exit, ele coloca o status da tarefa em EXITED (para assim aproveitar seu PCB para novas tarefas) e novamente chama a função scheduler_entry. Muito suspeito.
Afinal, o que essa scheduler_entry faz? Muita calma, pois esse é o coração da troca de contexto, e qualquer vacilo faz com que o kernel pare de funcionar (acredite em mim).
Esse é o caminho crítico, é nesse trecho que há o salvamento e restauração da do estado das tarefas. O problema é salvar o estado, usando instruções do processador que não alterem o estado sendo salvo.
Não entendeu? A maioria das instruções alteram o estado do processador, e por estado eu digo o registrador EFLAGS. Fez uma operação matemática e deu overflow? O Campo OF (Overflow Flag) é alterado. Fez uma operação matemática e deu zero? O campo ZF (Zero Flag) é alterado. Fez operações que teve o vai-um no último bit? O campo CF (Carrier Flag) é alterado. Fez operações de movimentação de bytes? O campo DF (Direction Flag) pode ser alterado. Um simples cálculo de deslocamento de bytes dentro de uma estrutura pode mudar o estado do processador, dependendo de como é feito.
Por sorte, algumas instruções não mudam o estado: push/pop, mov, lea. Essas podemos usar. Então, meu algoritmo para salvar o estado é o seguinte:
Começamos criando o registro de ativação da função scheduler_entry, como de costume. Portanto,
push ebp/mov ebp, esp.Preciso salvar o endereço de esp em algum ponto. Esse é o endereço da pilha da tarefa em execução, e você já vai entender o motivo. Por sorte, o registor de ativação já fez isso pra gente, esse valor está em
ebpagora.Enquanto conseguimos salvar alguns registradores individualmente com operações
pushemov, isso não é possível para o EFLAGS. A ÚNICA forma de se fazer isso é usando a instruçãopushfd. E isso é feito na pilha. Já que essa é a saída, temos uma instrução que salva todos os registradores de propósito geral de uma vez: a instruçãopushad.Mas executar isso com a pilha desse jeito não me adianta, eu preciso salvar em um lugar específico para restauração posterior: no PCB da tarefa ativa. Por sorte, essa estrutura está na variável
current_task.Eu preciso enganar estão o processador, apontar
esppara essa estrutura e fazer as operações depush. Na verdade, lembre-se que a pilha cresce para baixo. Eu preciso calcular quantos bytes essas instruções pushfd e pushad salvam, de modo que ao final desses dois pushs, o endereço apontado por esp seja igual ao do início da estrutura PCB ativa. No nosso caso, são salvos 9 registradores de 32 bits (EDI, ESI, EBP, original ESP, EBX, EDX, ECX, EAX, EFLAGS). Portanto, 9 vezes 4. Nesse ponto, esses 9 registradores estão salvos em uma área da memória, especificamente no PCB da tarefa em execução.Note no passo anterior que ele está salvado o
esporiginal da chamada da instruçãopushad. Contudo, quando executo essa instrução,espestá apontando para oPCB, e não para uma pilha válida. Mas por sorte temos esse valor, ele está emebpcomo dito anteriormente. Salvamos esse valor também noPCB.A tarefa está completamente salva. Restaure o endereço válido da pilha, para que as próximas instruções possam utilizar de forma correta. Novamente, esse endereço está em
ebp.Chame a função
schedulerpara escolher a próxima tarefa apta.
A função de salvar o estado está completa, e mostrarei ela logo mais. Para melhor entendimento, vamos ver o que essa função scheduler faz.
extern "C" void scheduler() {
sched.inc_count();
current_task = sched.get_ready_task();
current_task->get().run();
}Então essa função só incrementa o contador do escalonador, pega uma nova tarefa apta e a coloca para “rodar” (na real ele só altera o status para RUNNING). O segredo aqui é que, ao final dessa função, a variável current_task foi alterada para uma nova tarefa!
E se uma nova tarefa foi escolhida, é hora de restaurarmos o estado dela. Como fazemos isso? Siga o algoritmo abaixo:
Quando a função
schedulerencerra,espainda está apontando para a pilha da tarefa anterior. Fazemos o mesmo truque e apontamosesppara oPCBda tarefa ativa (current_task).Faremos a operação inversa, usando instruções
popadepopfd. Dessa vez, apontamos para o início da estrutura mesmo. As instruçõespopincrementam o valor deespe portanto esse endereço parte do início doPCBe vai até onde salvamos todos os registradores (note a importância desse primeiro membro da estruturaPCB-regs[9]).EM TEORIA, os registradores já possuem todos os valores restaurados. Em teoria, pois se você ver o manual da instrução
popad2, verá que esp não vem doPCB, afinal, a própria instruçãopopadmanipula esse registrador. Não tem problema. Depois do fim da execução depopadepopfd, temos certeza que esp está apontando para&PCB + sizeof(regs[9]). Se fizermos[esp - (6*4)], pegaremos o valor salvo deregs[3], que é o nossoespsalvo.
E é isso. Ao final desse processo, temos o esp apontando para o registro de ativação da tarefa atual, que empilhou o endereço de retorno (com a instrução call) e o ebp antigo (com a instrução push ebp, no começo da função para estabelecimento do registro de ativação). A função termina fazendo pop ebp e ret, retornando para a tarefa que foi escolhida pelo escalonador.
Eu apresentei algoritmos até agora pois esses passos são feitos em assembly. Segue o conteúdo do arquivo entry.asm.
global scheduler_entry
extern current_task, scheduler
scheduler_entry:
push ebp
mov ebp, esp
mov esp, [current_task]
lea esp, [esp + (9*4)]
pushfd
pushad
mov [esp + (3*4)], ebp
mov esp, ebp
call scheduler
mov esp, [current_task]
popad
popfd
mov esp, [esp - (6*4)]
pop ebp
retDepois que está pronto, até parece simples. Mas o segredo é o valor de current_task quando a função inicia não é o mesmo de quando ela termina. Tanto essa variável como a função scheduler estão definidos no arquivo scheduler.cpp e por isso são marcados como externos.
Para finalizar, temos apenas que ter cuidado com a primeira vez que a função scheduler_entry é invocada. Afinal, quando isso acontece, não há nenhuma tarefa ativa escolhida pelo escalonador, quem está chamando essa função é a função principal _start do kernel.
Para resolver isso, criei um PCB espantalho, e já inicio o current_task apontando para ele.
Datastructure::QueueNode<PCB> dummyPCB;
Datastructure::QueueNode<PCB> *current_task = &dummyPCB;Assim, quando a scheduler_entry é invocada a primeira vez, a função irá salvar os valores dos registradores e pilha em dummyPCB. Como não há intenção de retornar a execução de _start depois que o escalonador for invocado, a função scheduler_entry salvará o estado em dummyPCB, mas depois que a função scheduler for invocada, uma tarefa válida já terá sido escolhida.
Você poderia se perguntar: não seria mais fácil usar uma flag e testar se a primeira vez? O problema disso é justamente que as instruções de desvio dependem de alteração das EFLAGS (é assim que elas funcionam inclusive). Portanto, mas simples e direto é mandar salvar os registradores em um área morta mas a lógica global não é alterada.
No fim das contas então, a função _start adiciona as tarefas e chama a função do_exit. Essa função altera o estado da tarefa corrente para EXITED (e a tarefa corrente está apontando para dummyPCB). do_exit, por sua vez, invoca a scheduler_entry, como já falamos anteriormente. A função _start ficou assim então:
extern Scheduler sched;
extern "C" void _start() {
_init();
GDT::install_gdt();
Screen::clear_screen();
// test_queue();
sched.add_task(&thread1, true);
sched.add_task(&thread2, true);
do_exit();
while (true) {
/* BUSY LOOP*/
}
/*If code has landed here, something very wrong happened...*/
_fini();
}Achou fácil? Pois eu que fiz não achei. São muitos detalhes sórdidos para que isso funcione a contento. O resultado pode ser visto no vídeo abaixo.
A lista de objetos no Makefile aumentou, agora temos:
OBJS:=screen.o gdt.o util.o tasks.o scheduler.o entry.o queue-impl-int.o queue-impl-pcb.oMas perto do que acabamos de mostrar, isso ai é fichinha e foi só para conhecimento. O código completo pode ser visto no meu github.
https://www.felixcloutier.com/x86/pusha:pushad
https://www.felixcloutier.com/x86/popa:popad